This post was imported from my old Drupal blog. To see the full thing, including comments, it's best to visit the Internet Archive.
My last post showed a visualisation of the Guardian’s MP’s Expenses data, ported into a Talis triplestore. Here’s a screenshot of another one (follow the link for the interactive version). The files that are used to create it are attached to this post.
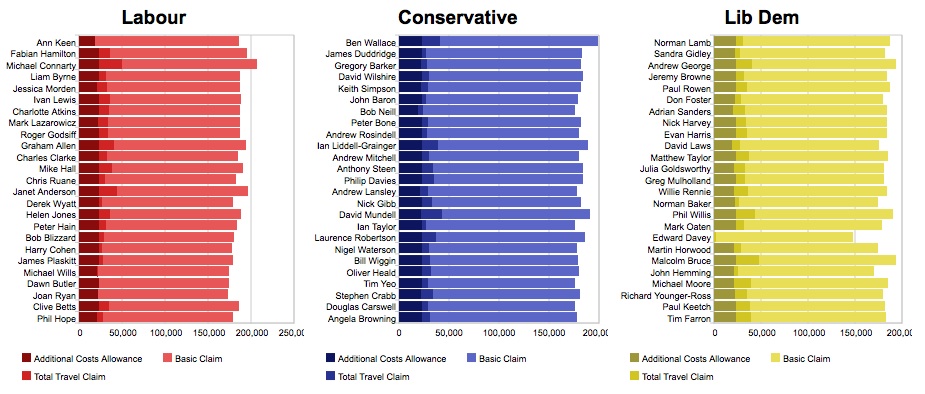
There are several things that are frustrating about creating these visualisations, which I want to discuss because I think they lead to some lessons about what data publilshers and members of the semantic web community should do to make these things easy. The first thing I want to talk about is datatyping.
In RDF, literal values can be plain literals, in which case they may have an associated language; XML literals, in which case they have structure; or typed literals, which have a particular datatype, usually one of the ones defined by XML Schema.
The easiest kinds of literals to create, especially in RDF/XML, are plain literals. Indeed some formats don’t even support the creation of typed literals. So RDF often contains values that are actually numbers or dates, but that are plain literals rather than being typed with an appropriate datatype.
In the RDF for the MP’s expenses data, many of the figures are typed as xsd:int but some (such as salary and total claim) are untyped. Which means that:
- sorting on them within the SPARQL query is done alphabetically rather than numerically
- automated conversions into, say, JSON, will usually convert them into strings rather than numbers, or have to take a stab in the dark and assume that they are numeric based on their format
When I created the visualisation shown above, for example, I did a sort on the total-claim property to get the top 25 claimants, but that wasn’t what I actually got because I wasn’t sorting on a number.
Now the question of whether an element’s value intrinsically has a particular type or is merely given a type for the purposes of processing is something that has caused religious wars within the XML community. And in those wars I have always come down firmly on the side of typing being a matter of interpretation.
But with RDF I think it’s different, for two reasons:
First, unless I’m mistaken (and excepting extensions that may have been made by individual processors) the main mechanism that we have for processing RDF – SPARQL – does not support casting a plain literal into a typed literal. So there is simply no way of sorting numerically based on a plain literal. This could be viewed as a deficiency of SPARQL which might be addressed in a future version.
Second, one of the much-cited advantages of RDF is that it is self-describing. You can make requests to the URIs used for properties and classes to find out more information about them. But self-describing should apply to literal values too. If a value is a date, it should be labelled as a date; if it’s a number it should be labelled as a number.
So how about these as guidelines for creating RDF that would make processing RDF easier:
- if the literal is XML, it should be an XML literal (obviously)
- if the literal is in a particular language (such as a description or a name), it should be a plain literal with that language
- otherwise it should be given an appropriate datatype