This post was imported from my old Drupal blog. To see the full thing, including comments, it's best to visit the Internet Archive.
Updated to include some of Arto Bendicken’s recommendations.
This post is a response to Richard Pope’s Linked Data/RDF/SPARQL Documentation Challenge. In it, he asks for documentation of the following steps:
- Install an RDF store from a package management system on a computer running either Apple’s OSX or Ubuntu Desktop.
- Install a code library (again from a package management system) for talking to the RDF store in either PHP, Ruby or Python.
- Programatically load some real-world data into the RDF datastore using either PHP, Ruby or Python.
- Programatically retrieve data from the datastore with SPARQL using using either PHP, Ruby or Python.
- Convert retrieved data into an object or datatype that can be used by the chosen programming language (e.g. a Python dictionary).
I’ve been told so many time how RDF sucks for mainstream developers that it was the main point of my TPAC talk late last year. I think that this is a great motivating challenge for improving not only the documentation of how to use RDF stores and libraries but how to improve their generally installability and usability for developers as well.
Anyway, I thought I’d try to get as far as I could to see just how bad things really are. I am on Mac OS X, and I’m going to use Ruby (although I don’t really know it all that well, so please forgive my mistakes). I’ll breeze on through as if everything is hunky dory, but there are some caveats at the end.
4store
I’m going to use 4store because it’s really easy to install on the Mac. If you want to install it on Ubuntu, there’s a package available. For a Mac, it’s a matter of going to the list of Mac downloads, downloading the most recent version, opening the .dmg and installing the 4store application by dragging it into your Applications folder.
When you run the 4store application you get a command line prompt. To set up and start a triplestore called ‘reference’ with a SPARQL endpoint running on port 8000, type the following commands:
$ 4s-backend-setup reference
$ 4s-backend reference
$ 4s-httpd -p 8000 reference
If you then navigate to http://localhost:8000/ you should see the following:
Don’t let the title ‘Not found’ put you off. The fact you get a response means that it’s working.
Loading Data
First, find some data to load. A good place for government RDF data is http://source.data.gov.uk/data/ for example. I downloaded
http://source.data.gov.uk/data/reference/organogram-co/2010-10-31/index.rdf
There are several ways of importing data into 4store using the command line. Yves Raimond has created a Ruby gem for doing so programmatically. There’s also rdf-4store from Fumihiro Kato which ties into the RDF.rb library which I’ll use later on.
However, if you use the SPARQL server then it’s just an HTTP PUT call, which of course you can do in any language you like (every language has support for making HTTP requests, right?) without the need to install any store-specific packages. However, since we’ll be doing a lot of HTTP requests, it’s useful to have a library that can make them simple. There are plenty to choose from for Ruby. I chose rest-client:
$ sudo gem install rest-client
With that, I wrote the following little Ruby script called ‘load-data-into-4store.rb’:
#!/usr/bin/env ruby
require 'rubygems'
require 'rest_client'
filename = '/Users/Jeni/Downloads/index.rdf'
graph = 'http://source.data.gov.uk/data/reference/organogram-co/2010-06-30'
endpoint = 'http://localhost:8000/data/'
puts "Loading #{filename} into #{graph} in 4store"
response = RestClient.put endpoint + graph, File.read(filename), :content_type => 'application/rdf+xml'
puts "Response #{response.code}:
#{response.to_str}"
Run the script from the command line:
$ ruby load-rdf-into-4store.rb
and you should get the response:
Sending PUT /data/http://source.data.gov.uk/data/reference/organogram-co/2010-06-30 to localhost:8000
Response 201:
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head><title>201 imported successfully</title></head>
<body><h1>201 imported successfully</h1>
<p>This is a 4store SPARQL server.</p><p>4store v1.0.5</p></body></html>
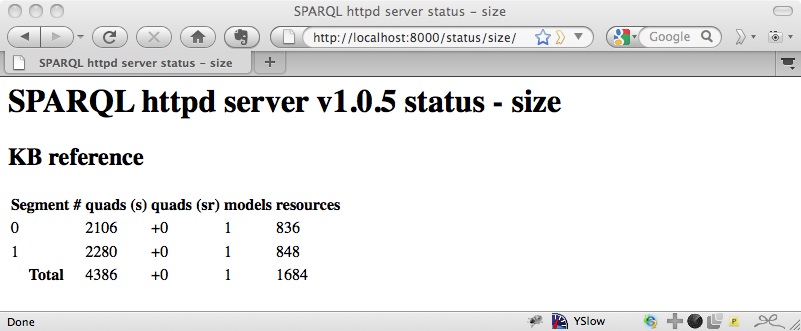
You can then check http://localhost:8000/status/size/ and you should see that there are now some triples in the store:
Running a Query
The next step is to query that data using SPARQL. Running SPARQL queries is just a matter of HTTP POSTing a query to the SPARQL endpoint. 4store provides a page that you can use to test out queries at http://localhost:8000/test/ so perhaps we should do that before diving into the Ruby code. The easy one to start with is just one that returns a list of the types of things that are described within the data:
SELECT DISTINCT ?type
WHERE {
?thing a ?type .
}
ORDER BY ?type
Paste that into the textarea that’s provided on http://localhost:8000/test/ so it looks like:
and you get some XML:
<?xml version="1.0"?>
<sparql xmlns="http://www.w3.org/2005/sparql-results#">
<head>
<variable name="type"/>
</head>
<results>
<result>
<binding name="type"><uri>http://purl.org/linked-data/cube#DataSet</uri></binding>
</result>
<result>
<binding name="type"><uri>http://purl.org/linked-data/cube#DataStructureDefinition</uri></binding>
</result>
...
</results>
</sparql>
SELECT queries like this one (which are the most common kind of query to run to simply extract data) return SPARQL Query Results XML Format by default, so there’s no need to get hold of a specialised library for processing the results: you just need something to process XML.
For Ruby, I’m choosing Nokogiri as I’ve heard good things about it. To install:
$ sudo port install libxml2 libxslt
$ sudo gem install nokogiri
So now we just need a script that will run this query, process the results as XML, and do something with them. Call it ‘find-rdf-types.rb’:
#!/usr/bin/env ruby
require 'rubygems'
require 'rest_client'
require 'nokogiri'
query = 'SELECT DISTINCT ?type WHERE { ?thing a ?type . } ORDER BY ?type'
endpoint = 'http://localhost:8000/sparql/'
puts "POSTing SPARQL query to #{endpoint}"
response = RestClient.post endpoint, :query => query
puts "Response #{response.code}"
xml = Nokogiri::XML(response.to_str)
xml.xpath('//sparql:binding[@name = "type"]/sparql:uri', 'sparql' => 'http://www.w3.org/2005/sparql-results#').each do |type|
puts type.content
end
Run it:
$ ruby find-rdf-types.rb
and you get:
POSTing SPARQL query to http://localhost:8000/sparql/
Response 200
http://purl.org/linked-data/cube#DataSet
http://purl.org/linked-data/cube#DataStructureDefinition
http://purl.org/linked-data/cube#Observation
http://purl.org/net/opmv/ns#Artifact
http://purl.org/net/opmv/ns#Process
http://purl.org/net/opmv/types/google-refine#OperationDescription
http://purl.org/net/opmv/types/google-refine#Process
http://purl.org/net/opmv/types/google-refine#Project
http://rdfs.org/ns/void#Dataset
http://reference.data.gov.uk/def/central-government/AssistantParliamentaryCounsel
http://reference.data.gov.uk/def/central-government/CivilServicePost
http://reference.data.gov.uk/def/central-government/Department
http://reference.data.gov.uk/def/central-government/DeputyDirector
http://reference.data.gov.uk/def/central-government/DeputyParliamentaryCounsel
http://reference.data.gov.uk/def/central-government/Director
http://reference.data.gov.uk/def/central-government/DirectorGeneral
http://reference.data.gov.uk/def/central-government/ParliamentaryCounsel
http://reference.data.gov.uk/def/central-government/PermanentSecretary
http://reference.data.gov.uk/def/central-government/PublicBody
http://reference.data.gov.uk/def/central-government/SeniorAssistantParliamentaryCounsel
http://reference.data.gov.uk/def/intervals/CalendarDay
http://www.w3.org/2000/01/rdf-schema#Class
http://www.w3.org/ns/org#Organization
http://www.w3.org/ns/org#OrganizationalUnit
http://xmlns.com/foaf/0.1/Person
So we can see that the dataset contains information that include statistical data using the data cube vocabulary, provenance information using OPMV (Open Provenance Model Vocabulary), some information about organisations using org, some data.gov.uk-specific vocabulary, and people using FOAF.
Processing RDF
Sometimes it can be useful to get non-tabular data out of SPARQL. At that point, rather than using SELECT queries, you will want to use a CONSTRUCT query, which creates RDF. For example, try the query:
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
CONSTRUCT {
?person
a foaf:Person ;
foaf:name ?name ;
?prop ?value .
} WHERE {
?person a foaf:Person ;
foaf:name ?name ;
?prop ?value .
}
This gets all the information in the data about the individuals for whom names have been supplied in the data, as RDF.
Although the response is RDF/XML, you definitely do not want to process it as XML. Instead, you need a proper RDF library. Fortunately, there’s a good one for Ruby in RDF.rb. You can install it and a bunch of extra plugins that make it easy to deal with RDF in all its guises using:
$ sudo gem install linkeddata
This lets us pick out an appropriate parser based on the Content-Type of the response, and load the results of the SPARQL query into an in-memory RDF::Graph:
response = RestClient.post endpoint, :query => query
content_type = response.headers[:content_type][/^[^ ;]+/]
puts "Response #{response.code} type #{content_type}"
graph = RDF::Graph.new
graph << RDF::Reader.for(:content_type => content_type).new(response.to_str)
We can perform subsequent queries over that graph, for example just to extract names and telephone numbers and put them into a dictionary:
query = RDF::Query.new({
:person => {
RDF.type => FOAF.Person,
FOAF.name => :name,
FOAF.mbox => :email,
}
})
people = {}
query.execute(graph).each do |person|
people[person.name.to_s] = person.email.to_s
end
It’s worth noting that the constants RDF and FOAF are pre-declared by including RDF, and the values that you get back from a query are RDF values, which can be URIs or have datatypes or languages. In the above code I’ve converted them into strings for insertion into the Ruby dictionary.
The full script for ‘get-names-and-emails.rb’ is:
#!/usr/bin/env ruby
require 'rubygems'
require 'rest_client'
require 'linkeddata'
include RDF
query = "PREFIX foaf: <http://xmlns.com/foaf/0.1/>
CONSTRUCT {
?person
a foaf:Person ;
foaf:name ?name ;
?prop ?value .
} WHERE {
?person a foaf:Person ;
foaf:name ?name ;
?prop ?value .
}"
endpoint = 'http://localhost:8000/sparql/'
puts "POSTing SPARQL query to #{endpoint}"
response = RestClient.post endpoint, :query => query
content_type = response.headers[:content_type][/^[^ ;]+/]
puts "Response #{response.code} type #{content_type}"
graph = RDF::Graph.new
graph << RDF::Reader.for(:content_type => content_type).new(response.to_str)
puts "\nLoaded #{graph.count} triples\n"
query = RDF::Query.new({
:person => {
RDF.type => FOAF.Person,
FOAF.name => :name,
FOAF.mbox => :email,
}
})
people = {}
query.execute(graph).each do |person|
people[person.name.to_s] = person.email.to_s
end
puts "\nCreating directory of #{people.length} people"
stott_email = people['Andrew Stott']
puts "\nAndrew Stott's email address: #{stott_email}"
Run this script with:
$ ruby get-names-and-emails.rb
and you get the result:
POSTing SPARQL query to http://localhost:8000/sparql/
Response 200 type application/rdf+xml
Loaded 459 triples
Creating directory of 75 people
Andrew Stott's email address: mailto:andrew.stott@cabinet-office.gsi.gov.uk
Conclusions and Caveats
So there you have it, a walkthrough of setting up a local triplestore, loading in data and accessing that data programmatically using SPARQL queries.
Now for some caveats. First, you’re bound to have noticed that I having followed Richard’s steps to the letter.
- 4store wasn’t installed from a package management system. The only packaged triplestore I could locate on MacPorts was Virtuoso (which I’ll come to in a second). I hope that 4store’s installation is simple enough for this slight deviation from the rules not to matter.
- I didn’t install a package for specifically talking to 4store in order to load in data, just used HTTP requests. There are client libraries for 4store, but I figure that the HTTP requests are easy enough, and the resulting code more portable into other environments, so I prefer not to use them.
Second, there are a couple of dead ends that I went down that I haven’t written up in the above:
- I did spend some time yesterday evening trying to get Virtuoso set up. I managed to get it installed, but loading data into it seemed to require some magic which I couldn’t figure out. So I went to bed instead.
- I tried to install and use rdf-raptor in order to parse the RDF/XML that naturally comes out of 4store CONSTRUCT queries, but got a
Could not open library 'libraptor'error. I couldn’t find an immediate fix for that, so decided to keep things simple instead and just use plain RDF.rb.
Third, I want to reiterate that there may be better ways of using 4store, rest_client, Nokogiri and RDF.rb, as well as Ruby generally, than those shown above. I don’t claim to be an expert in any of these technologies. If you have suggestions and corrections, I’d encourage you to add a comment and I’ll incorporate them in the text to improve it.
Finally, some general points, because the strong binding of ‘linked data’ and ‘SPARQL’ in Richard’s post bothers me:
- It’s not necessary to have a SPARQL endpoint when publishing linked data, nor to run your own triplestore. If you already have a website, you are probably better off generating N-Triples or RDF/XML or Turtle in the same way as you generate HTML or XML or JSON.
- It’s not necessary to learn SPARQL to access and use linked data: the whole point is that the data in linked data is available through HTTP access in standard (RDF-based) formats, so you can scrape them using a follow-your-nose approach and store the results however you like.
Having said the above, if you’re collecting linked data from multiple sources with unpredictable content and want to query across it, having a local triplestore is very useful.
I also want to point out that within the linked data we’ve published on data.gov.uk, we’ve made a big effort to make the data available in multiple formats such as JSON, XML and CSV, and through a RESTful, URI-parameter-driven API, precisely to lower the barrier for developers who want to use that information but understandably don’t want to take the time or make the effort to learn the linked data technologies that underly the sites. For those that do, the RDF/XML and Turtle is there as well, and the SPARQL queries that are used to create each page are available to look at, tweak, and learn from. Our hope is that the linked data API that provides access to lists of schools, departments and railway stations can make the linked data learning curve a little less steep.